
Język Lua nie udostępnia wprost możliwości działania na obiektach. Jest za to jedna z możliwości, jak taki sposób uzyskać. Z pomocą przychodzą nam
metatablice
. Jako, iż wikipedia nie jest zbyt wymowna na ich temat, pozwolę sobie skonstruować prostą do zrozumienia definicję na potrzebę ów artykułu.
Metatablice są to tablice zawierające określony zestaw zachowań, na które jest w stanie zareagować wartość. Każda wartość ma swoją metatablicę, która reguluje to, w jaki sposób np. liczba 5 zareaguje na próbę wykonania na niej operacji dodawania.
Znając teraz uproszczoną definicję metatablicy, możemy przejść przez kawałek teorii związanej z tym zagadnieniem. W Lua mamy do czynienia z prostą dwuwymiarową tablicą, która jest wywoływana przez interpreter w każdym przypadku, gdy coś wyda mu się nie do końca poprawne. Weźmy sobie za przykład wartość nieliczbową, np. tablicę jednowymiarową. Co się stanie, gdy nasza tablica zostanie operandem dodawania? Interpreter zwróci uwagę na to, że chcemy dodać do czegoś wartość nieliczbową i zwróci się do metatablicy podając zdarzenie
add
. Metatablica zwróci za to metametodę (wartość pod kluczem
__add
) odpowiadającą temu zdarzeniu, co pozwoli nam (lub nie, w zależności od tego czy metametoda istnieje) wykonać operację dodawania na tej wartości. Zrzucając szatę możliwego niezrozumienia pojęć pozwolę sobie wytłumaczyć użyte przeze mnie dwa nowe pojęcia.
Zdarzenie
to po prostu klucz tablicy, a
metametoda
to funkcja, która zostanie wykonana w przypadku wywołania danego zdarzenia. Brzmi znajomo? Już za moment wszystko powinno stać się zrozumiałe.
Szukając porówniania do innych języków, przykładem dla nas mogą okazać się przeciążenia operatorów w języku C#. Idea działania jest praktycznie taka sama.
Jeżeli teraz połączymy te informację z inną, która mówi nam, że te metatablice można, tak jak w językach typu C#, przeciążać, to dojdziemy do wniosku, że z dużą dozą prawdopodobieństwa uda nam się napisać bardzo dobrze działający „kod zorientowany obiektowo”. Możemy teraz przejść do praktycznej części.
Rozpocznijmy naszą praktykę od utworzenia metatablicy oraz nadpisania jej zdarzenia.
Utworzyliśmy teraz metatablicę
Account
, której wartość zdarzenia
index
ustawiliśmy na nią samą. Dzięki czemu obiekty będą mogły korzystać z metod zdefiniowanych w tej tablicy. Na tym jednak nie poprzestajemy.
Tym razem zdefiniowaliśmy metodę
create
, która pozwoli nam na utworzenie „obiektu” naszej tablicy. Nasz trik polega na utworzeniu pustej tablicy, której wstrzykniemy naszą spreparowaną metatablicę. Następna linijka odpowiada za „konstruktor” naszego obiektu, czyli zapisanie właściwości
balance
przekazanej z wywołaniem metody
create
. Na sam koniec zwracamy nowo utworzony „obiekt”. Nie mielibyśmy jednak obiektu, gdyby nie chociaż jedna metoda poza konstruktorem. Utwórzmy więc takową.
Prosta metoda umożliwiająca podanie w argumencie liczby o którą uszczuplimy właściwość
balance
naszego obiektu. Skorzystaliśmy sobie w niej z parametru self, który umożliwia nam ominięcie odniesienia do globalnej wartości
Account
. Jest to dobra praktyka, która warto sobie przyswoić.
Jeżeli jesteś osobą, która lepiej czuje się z użyciem parametru
this
niż
self
, istnieje możliwość zmiany tego parametru. W tym celu, przy tworzeniu definicji metody, zamiast
:
korzystamy z operatora
.
. Wówczas w pierwszym argumencie możemy wpisać
this
lub cokolwiek innego, dzięki czemu zmienna ta stanie się reprezentacją naszego obiektu w tej definicji.
Do testów starczy nam to w zupełności. Utwórzmy teraz jeden obiekt i skorzystajmy z metody.
Prześledźmy teraz działanie tych dwóch linijek kodu, aby lepiej zrozumieć co się stanie. Pierwsza linijka to po prostu utworzenie obiektu na bazie klasy
Account
. Działanie tej metody wytłumaczyliśmy sobie parę akapitów wyżej. Druga linijka natomiast nie jest tak oczywista jak mogłoby się wydawać. Odwołanie do metody tablicy
acc
zwróci błąd, ponieważ nic takiego nie istnieje. Interpreter wie natomiast, że
acc
to tablica, tak więc podejmie próbę wyszukania indeksu tej tablicy. I tutaj wkracza do akcji przygotowana przez nas metatablica, która umożliwia nam dostanie się do zasobów tablicy
Account
. I tym sposobem utworzyliśmy nasz pierwszy pełnoprawny obiekt w języku Lua!
Czy istnieje jednak prostsze podejście do obiektowości w Lua? Okazuje się, że tak. Co więcej, być może uda nam się nawet użyć dziedziczenia! To jednak materiał na kolejny artykuł.
Artykuł bazujący na zawartości strony: http://lua-users.org/wiki/SimpleLuaClasses
]]>
Moimi ulubionymi modyfikacjami okazały się dodatki przemysłowe, dodające kolejne stopnie przerabiania surowców oraz maszyny ułatwiające ich przetwarzanie. Każdy, kto chociaż trochę zainteresuje się uprzemysłowieniem produkcji zawsze dobrnie do momentu, w którym ręczne operowanie całą fabryką straci sens, ponieważ nie jest to już takie efektywne jak to, czego się oczekiwało. W takim przypadku z pomocą przychodzą nam komputery.
W tym poradniku przedstawię rozwiązanie architektury klient – serwer na jednej z dwóch najpopularniejszych modyfikacji dodającej maszyny liczące. Będzie to ComputerCraft . W kolejnych poradnikach skupię się na drugiej modyfikacji tego typu – OpenComputers . Ten poradnik skierowany jest do osób, które miały już styczność z językiem Lua oraz tą modyfikacją.
Architektura w teorii
Poradnik rozpocznę od cytatu z portalu Wikipedia.com:
Klient-serwer (ang. client/server, client-server model ) – architektura systemu komputerowego, w szczególności oprogramowania, umożliwiająca podział zadań (ról). Polega to na ustaleniu, że serwer zapewnia usługi dla klientów , zgłaszających do serwera żądania obsługi (ang. service request ).
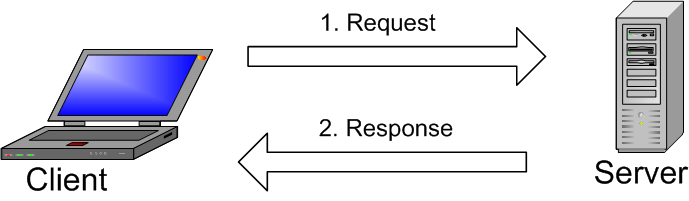
Najlepszym (moim zdaniem) przykładem takiej architektury jest relacja przeglądarka – serwer WWW . Na jakiej zasadzie działa takie połączenie? Przeglądarka wysyła do serwera żądanie (ang. request ) i oczekuje od serwera odpowiedzi (ang. response ). Kilka lat temu natknąłem się na określenie połączenia typu ping-pong , czyli połączenie polegające na przekazaniu pakietu danych razem z wirtualną „piłeczką”. Określenie osobliwe, jednakże nie odbiega znacznie od głównej idei a może ułatwić początkującym zrozumienie tego typu relacji.
Na obecnym etapie ujawniają się kolejne właściwości tego typu połączenia. Jedną z głównych jest zależność, z której wynika, że jeden serwer może przyjmować żądania od wielu klientów . Co jednak w momencie, w którym serwer otrzyma w tym samym momencie kilka żądań? Jest na to kilka rozwiązań, nie tylko sprzętowych ale również programowych. Czasem jest to dodatkowy serwer kolejki (ang. queue server ), który zostaje umieszczony pomiędzy klientem a serwerem i wysyła żądania serwerowi głównemu w kolejce, w której je otrzymał, bez jego przeciążania, a czasem program uruchomiony w tle , który przetrzymuje żądania w kolejce, a program serwera po kolei może je z niego wybierać. W tym przykładzie pominę to zagadnienie i skupię się głównie na samym połączeniu, bez rozwiązywania problemów z możliwymi przeciążeniami.
Projekt protokołu
Połączenie obu komputerów musi być w jakiś sposób ujednolicone , dlatego utworzyłem protokół (w ogromnym uproszczeniu), który korzysta z API Modemu ( link ). Sama modyfikacja udostępnia jeszcze API nazwane „Rednet” , jednakże pozwala ono tylko na połączenie po modemie bezprzewodowym, a sporządzając swój własny protokół można korzystać nie tylko z bezprzewodowych, ale i przewodowych modemów.
Identyfikacja komputerów w sieci w tej modyfikacji znacznie odbiega od właściwości protokołu TCP/IP . Każdy komputer posiada swój unikalny identyfikator i jest on niezmienny, niezależny od sieci, do której jesteśmy połączeni.
Sam projekt rozpocznę od ramki , czyli „piłeczki”, którą będziemy „rzucali” między komputerami. Obiekt ten musi zawierać wszystkie potrzebne informacje do działania protokołu jak i dane, które będziemy chcieli przekazać dalej. Oto lista:
-
ID adresata, czyli identyfikator komputera, z którego wysyłamy ramkę -
ID odbiorcy, czyli identyfikator komputera, do którego docelowo ma dotrzeć ramka -
Typ wiadomości, czyli ciąg znakowy identyfikujący typ zawartości ramki (np. obiekt, ciąg znakowy, liczba, typ logiczny…) -
Zawartość, czyli faktyczna wiadomość wysyłana w ramce
API Modemu pozwala na operowanie na kanałach – odpowiednikach portów w protokole TCP/IP. Chcąc uzyskać podobieństwo do protokołu HTTP , skorzystam z kanału 80 .
Oto konstrukcja obiektu ramki, którym będą wymieniały się komputery:
Cały protokół oparty jest na 2 funkcjach – odbierającej i wysyłającej. Funkcja odbiorcza przyjmuje 3 argumenty. Pierwszy,
wymagany
argument to kanał, na którym program ma nasłuchiwać. Pozostałe dwa argumenty są
opcjonalne
i nie trzeba ich wpisywać. Pierwszy z opcjonalnych to czas, przez który program ma nasłuchiwać do czasu zwrócenia błędu o braku odpowiedzi (ang.
timeout
). Domyślną wartością w tym przypadku będzie
10 sekund
, a maksymalną możliwą do wpisania będzie
120 sekund
. W argumencie tym można wpisać również wartość logiczną
false
, która zablokuje wywołanie timera, a co za tym idzie, nie pozwoli na zwrócenie błędu o braku odpowiedzi. Ta właściwość przyda się podczas pisania programu serwera. Drugi zaś to typ wiadomości, którego program oczekuje. Jeżeli ciąg znakowy wpisany w tym parametrze nie będzie zgodny z ciągiem podanym w ramce, program przystąpi do dalszego nasłuchu. Funkcje te są przystosowane do wykrycia modemu, tak więc w celu uniknięcia błędów/niepożądanego działania lepiej nie podłączać do komputera większej ich ilości.
Teraz można wywołać funkcję odbiorczą wpisująć
receive(kanał[, czas, typ])
. Funkcja
waitForMessage()
jest funkcją wewnętrzną wykorzystywaną przez funkcję
receive()
.
Funkcja nadawcza przyjmuje 2 argumenty. Oba są wymagane do jej działania. Pierwszy argument to obiekt ramki, który program chce przesłać. Drugi argument to kanał, po którym ramka ma zostać przesłana.
Aby wysłać wiadomość, wystarczy sporządzić odpowiedni obiekt żądania według wzoru ramki i wywołać funkcję
send(żądanie, kanał)
.
Obie funkcje można umieścić w jednym pliku i wywoływać je w innym (np. w programie serwera) poprzez załączenie ich jako API. Aby to zrobić, trzeba zapisać je w pliku o nazwie np.
protocol
i załadować je do programu jak w poniższym przykładzie. Potem będzie można odwoływać się do nich jak do metod obiektu.
Modyfikacja udostępnia API serwisu
Pastebin.com
do pobierania skryptów ze strony na komputery w grze. Aby umożliwić jednak korzystanie z tej funkcji, trzeba odnaleźć plik
ComputerCraft.cfg
i zmienić wartość linii
B:enableAPI_http=
z
false
na
true
. Wtedy będzie można skorzystać z tego udogodnienia. W celu pobrania protokołu wystarczy wpisać
pastebin get DfjzLK6R protocol
.
Schemat algorytmu
Poradnik przewiduje 2 programy. Pierwszy program ( klient ) będzie przyjmował od użytkownika komendę, po czym nastąpi jej przekazanie do serwera i oczekiwanie na odpowiedź. W przypadku otrzymania odpowiedzi nastąpi jej wyświetlenie, a w przypadku braku odpowiedzi w wyznaczonym czasie zostanie wyświetlony błąd o braku odpowiedzi z serwera. Po wyświetleniu błędu program zada pytanie użytkownikowi, czy ten życzy sobie ponownego wysłania żądania do serwera. Odpowiedź twierdząca powtórzy procedurę wysłania żądania, a przecząca zakończy program. Drugi program ( serwer ) będzie działał w wiecznej pętli, podczas której będzie oczekiwał zdarzenia (ang. event ) otrzymania żądania od klienta, po której nastąpi przetworzenie ów żądania i wystosowanie odpowiedniej odpowiedzi. Po wysłaniu wiadomości zwrotnej program przystąpi od początku do nasłuchiwania.
Algorytm programu klienta i serwera
Program klienta
Klient będzie prostym programem konsolowym, który będzie wysyłał komendy wprowadzone przez użytkownika do serwera i zwracał użytkownikowi odpowiedź serwera. W tym przypadku będą to komendy włączenia/wyłączenia lampki oraz zwrócenia stanu lampki (czy włączona). Do programu przyda się funkcja wysyłająca żądanie i zwracająca odpowiedź. Oto ona:
W funkcji tej utworzyłem obiekt żądania i wypełniłem go potrzebnymi danymi. Adres serwera oraz komendę wpisuje użytkownik podczas działania programu. Następuje teraz
bezpieczne wywołanie
funkcji wysłania żądania funkcją
pcall()
. W przypadku wystąpienia błędu, program nie zatrzyma się, a przekaże błąd do wyniku działania funkcji. Wtedy warunek w linii 10 wykryje takowy, jeżeli tylko się pojawi i wyświetli stosowny komunikat. Analogiczna sytuacja w przypadku funkcji odbierania odpowiedzi. Gdy wszystko będzie w porządku, funkcja zwróci wiadomość w postaci obiektu odpowiedzi.
Zgodnie z algorytmem, w pierwszej kolejności użytkownik musi podać wymagane informacje dotyczące identyfikatora serwera oraz komendy, którą zamierza przesłać. Pętlę rozwiązałem otaczając cały blok wprowadzania argumentu pętlą
repeat ... until
. Jest to pętla będąca odpowiednikiem
do ... while
w językach C-podobnych. W każdym bloku sprawdzam również zgodność typu danych oraz czy nie zwróciło fałszu lub pustej wartości (
nil
). Oto moje rozwiązanie:
Skoro jest już rozwiązane wprowadzanie i wysył/odbiór danych to pozostało oprogramować całość do końca. Trzeba zaimplementować mechanizm wyświetlania odpowiedzi i ponowienia wysłania ramki. Tutaj również użyłem pętli
repeat ... until
. Gdy program wykryje brak odpowiedzi, zaproponuje użytkownikowi ponowienie operacji. W tym przypadku użytkownik ma do wyboru naciśnięcie dwóch przycisków. Naciśnięcie przycisku
T
na klawiaturze spowoduje powtórzenie pętli, zaś naciśnięcie
N
zakończy działanie programu. Otrzymanie odpowiedzi spowoduje jej wyświetlenie i również zakończenie dalszych działań.
Teraz pozostało dołączyć API naszego protokołu i połączyć całą resztę ze sobą. Oto efekt:
Program klienta możemy pobrać na komputer w grze wpisując komendę
pastebin get 04ckzKNf client
Program serwera
Zadaniem serwera będzie kontrola lampki, która poleceniem klienta będzie mogła zostać zapalona lub zgaszona. Klient będzie mógł również poprosić serwer o podanie stanu lampki (czyli czy jest zapalona czy zgaszona). Program serwera rozpocznę od napisania paru funkcji do sterowania lampką:
Jak widać są to dwie funkcje – jedna do włączania lampki i druga do jej wyłączania. Każda z nich przyjmuje argument w postaci ciągu znakowego oznaczającego stronę komputera, po której został umieszczony przewód prowadzący do lampki. Obie funkcje mają ten sam mechanizm działania. W przypadku, gdy wykonywana przez nie operacja powiedzie się, zwracają logiczną prawdę. Każdy inny wynik operacji spowoduje zwrócenie logicznego fałszu. Tak więc jeżeli będziemy chcieli zapalić lampkę a ta będzie już zapalona, otrzymamy
false
.
Ciągi znakowe oznaczające strony to: top, bottom, left, right, front, back . Tłumacząc na język polski w kolejności: góra, dół, lewo, prawo, przód, tył .
Postępując zgodnie ze schematem algorytmu do napisania pozostały jeszcze 2 funkcje – przetwarzania żądania i odsyłania odpowiedzi.
Aby użyć funkcji odbiorczej w programie serwera wystarczy wpisać w argumencie funkcji odpowiadającym za czas oczekiwania wartość
false
. Nastąpi wtedy wyłączenie timer’a, który odpowiada za wywołanie błędu braku odpowiedzi. Pozwoli to programowi na działanie w wiecznej pętli nasłuchu bez konieczności napisania nowej funkcji.
Oto kod pętli programowej serwera. Tak jak napisałem wcześniej – wieczna pętla, w której program nasłuchuje wiadomości i odpowiada na żądania. Ale jak wygląda odpowiadanie i przetwarzanie tych żądań?
callback()
to prosta funkcja przyjmująca jako jedyny argument obiekt odpowiedzi serwera i wysyłający go zgodnie z danymi w nim zawartymi. Zadaniem funkcji
process()
jest przetwarzanie żądania, które otrzymał serwer, wykonywanie polecenia w nim zawartego i wystosowanie obiektu odpowiedzi.
Ułatwiłem sobie trochę zadanie poprzez utworzenie funkcji
prepareResponse()
, która zwraca mi kompletną konstrukcję obiektu, który potem zostanie użyty w funkcji
callback()
. Kod wygląda w ten sposób znacznie schludniej. Pokusiłem się również o dodanie prostej informacji wstępnej z ID komputera oraz stroną z kablem prowadzącym do lampki. Oczywiście stronę można sobie ustawić samemu edytując zmienną
side
.
Tak samo jak w przypadku kodu klienta, kod serwera również można pobrać w grze komendą
pastebin get q88vs6TJ server
Uruchomienie
Do działania potrzeba oczywiście dwóch komputerów. Każdy z nich powinien być wyposażony w modem. W przypadku modemów bezprzewodowych trzeba pamiętać o ograniczeniu odległości. Moja platforma testowa wygląda tak:
Komputer po lewej ma zainstalowany program klienta, ten po prawej zaś działa już jako serwer, z lampką podłączoną do tylnej ścianki. Oba łączą się za pomocą modemów bezprzewodowych. Najlepiej zacząć od wgrania protokołu oraz programu na komputer, który ma pełnić rolę serwera. Po uruchomieniu serwera trzeba zwrócić uwagę na dwie rzeczy:
Pierwsza rzecz to ID , czyli identyfikator serwera, który potem będzie trzeba wpisać w programie klienta. Druga rzecz to informacja po której stronie powinien znajdować się kabel prowadzący do lampki . Specjalnie dla początkujących spolszczyłem nazwy w programie. Jeżeli ta wartość jest inna niż zamierzona, trzeba zmienić ją w programie.
Podczas instalacji programu klienta jak i serwera należy pamiętać o równoczesnej instalacji protokołu . Bez tego program nie będzie w stanie zadziałać.
Teraz skupię się na programie klienta. Po wgraniu programu razem z protokołem można go uruchomić.
W tym momencie program wymaga wprowadzenia komendy. Jeżeli nie zostanie rozpoznana przez serwer, prześle on odpowiedź zwrotną z informacją o nierozpoznanej komendzie. Dla testu wprowadzę komendę
is_on
, która powinna zwrócić stan lampki.
Tutaj należy wpisać ID komputera, na którym zainstalowany jest program serwera. W moim przypadku ID wynosi 0. Po tym kroku nastąpi wysłanie informacji na serwer i oczekiwanie odpowiedzi. Kolejne okno pojawi się, gdy klient otrzyma wiadomość lub minie czas oczekiwania na wiadomość. W moim przypadku czas ten w protokole ustawiłem na 3 sekundy .
Po lewej stronie klient odebrał wiadomość od serwera, po stronie prawej natomiast tej odpowiedzi nie otrzymał i dał nam wybór na powtórzenie wysłania wiadomości.
Podsumowanie
Do czego można użyć takiej konfiguracji? Sterowanie jedną maszyną/fabryką z wielu miejsc, system wewnętrznych wiadomości, system kontroli dostępu… Możliwości jest naprawdę wiele. Sam system można naprawdę mocno rozbudować, na pewno w wielu miejscach również poprawić lub napisać na nowo – lepiej, wydajniej. Mam nadzieję, że ten poradnik będzie dla wielu przydatny i że chociaż odrobinę przybliżyłem piękno leżące w komunikacji sieciowej i jej możliwościach. Odpowiem na wszelkie pytania w komentarzach w ramach mojej najlepszej wiedzy. Nie bójcie się pytać. Każdy kiedyś zaczynał, a przykład takiej gry jak Minecraft , gdzie zastosowanie znajdują ogromne ilości nie tylko informatycznych zagadnień, tylko potwierdza regułę.
]]>